新万博移动客户端Collibra平台
在您的数据景观中获得完全可见性,在您的数据中找到意义并提高业务决策的质量
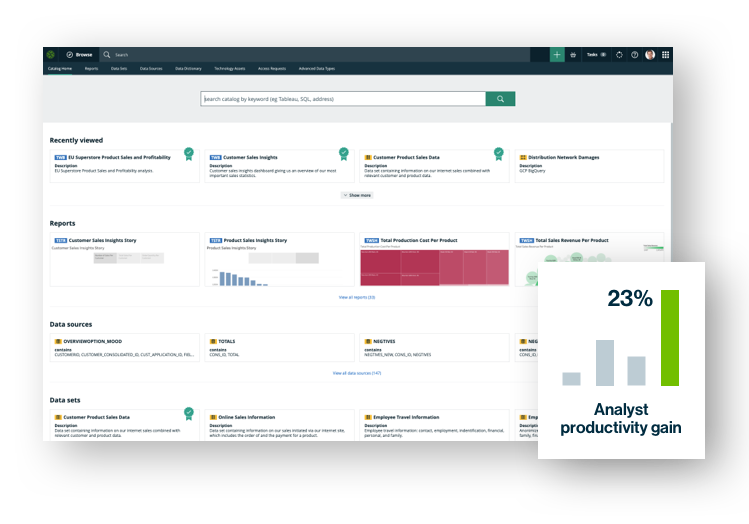
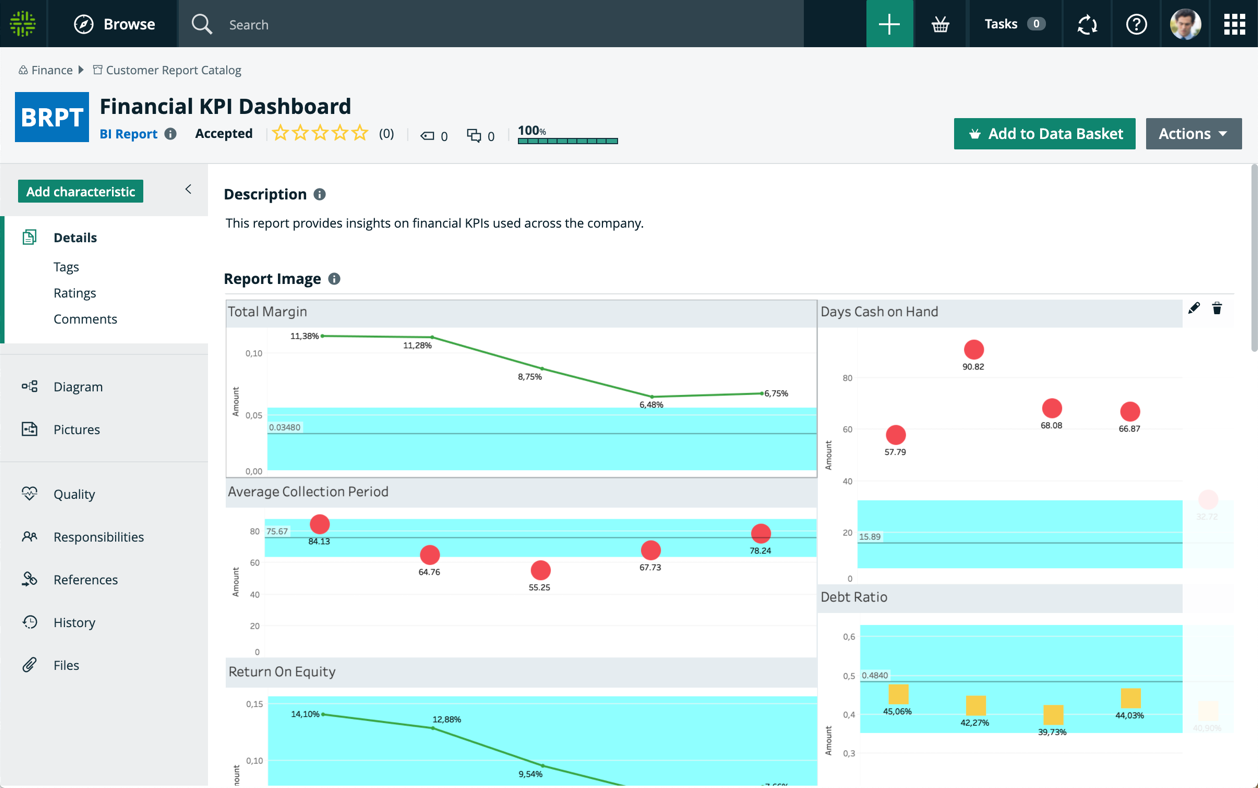
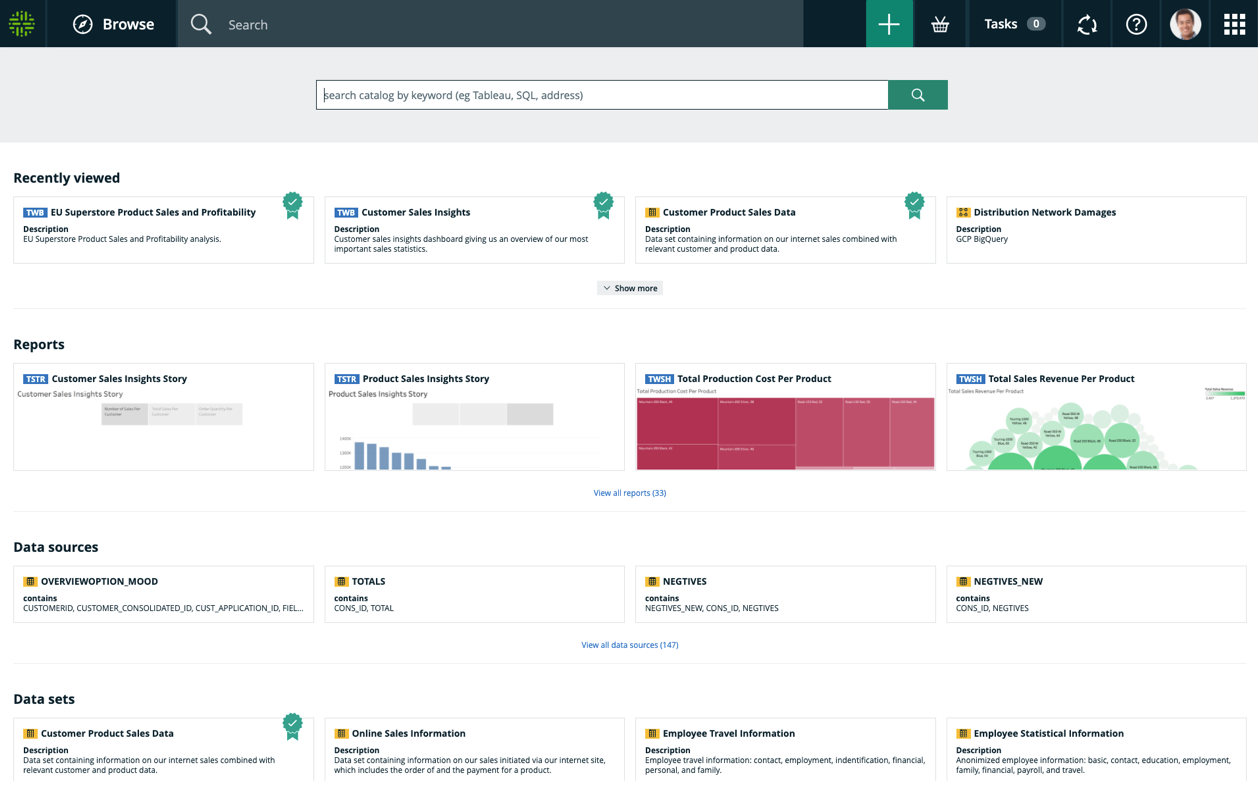
数据目录
发现并理解最重要的数据,以便您可以生成驱动业务价值的见解
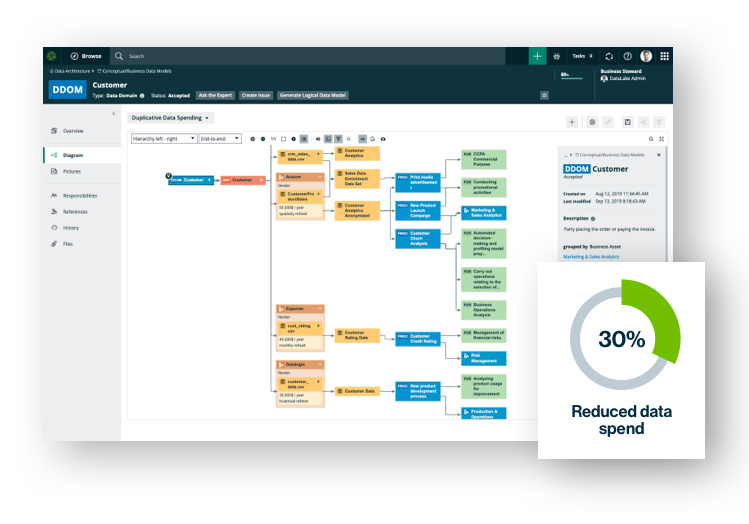
数据治理
建立共享的商务语言,了解您的不断发展的数据景观,可以使用可扩展的解决方案而与您一起增长
618manbetx
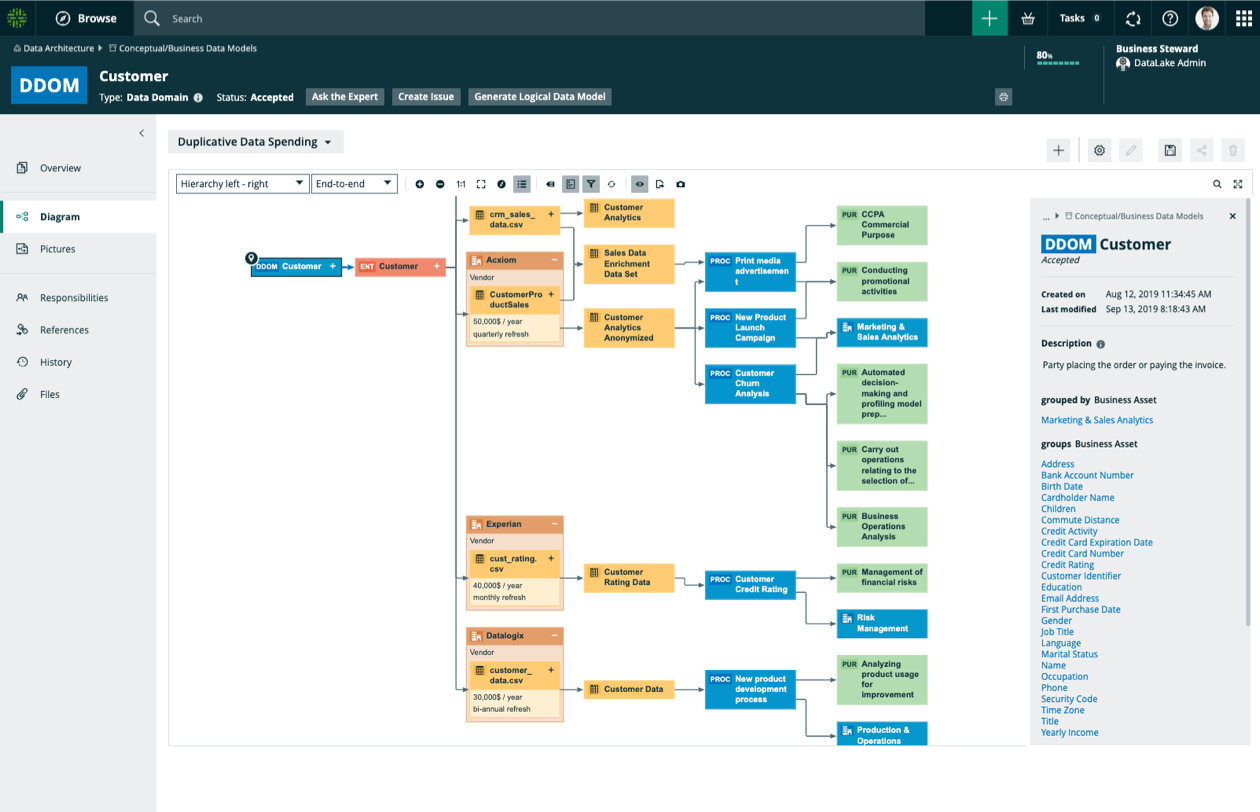
展示数据如何通过完整的端到端沿袭可视化从一个系统流到另一个系统
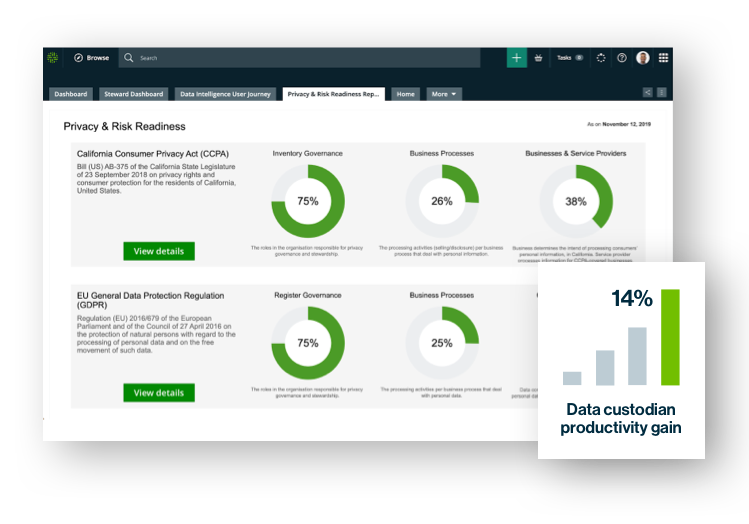
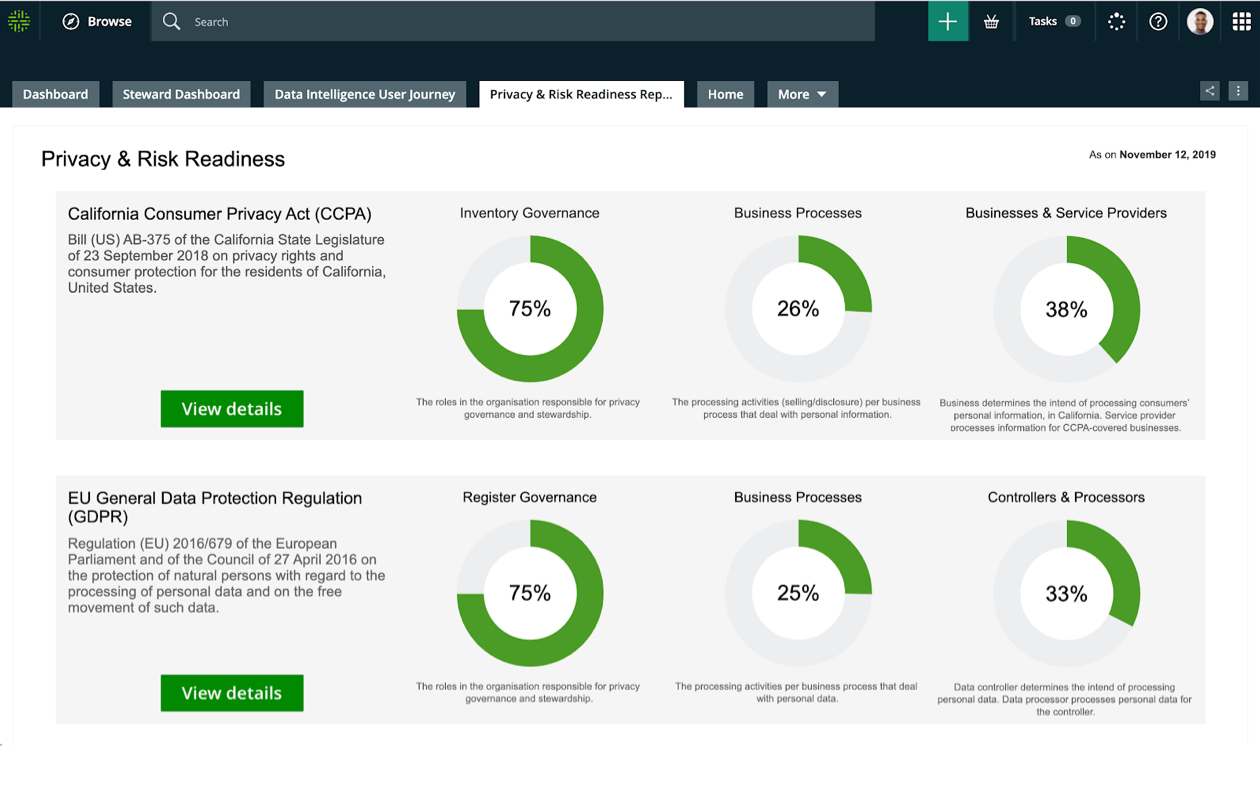
2018世界杯狗万滚球app
跨隐私生命周期操作和管理策略,并跨新法规扩展遵从性
354manbetx
自动生成数据质量规则,以不断提高对数据和分析的信任
333manbetx
信任在我们所做的一切中发挥作用